From the conversion glossary
Concepts referenced in this article, defined.
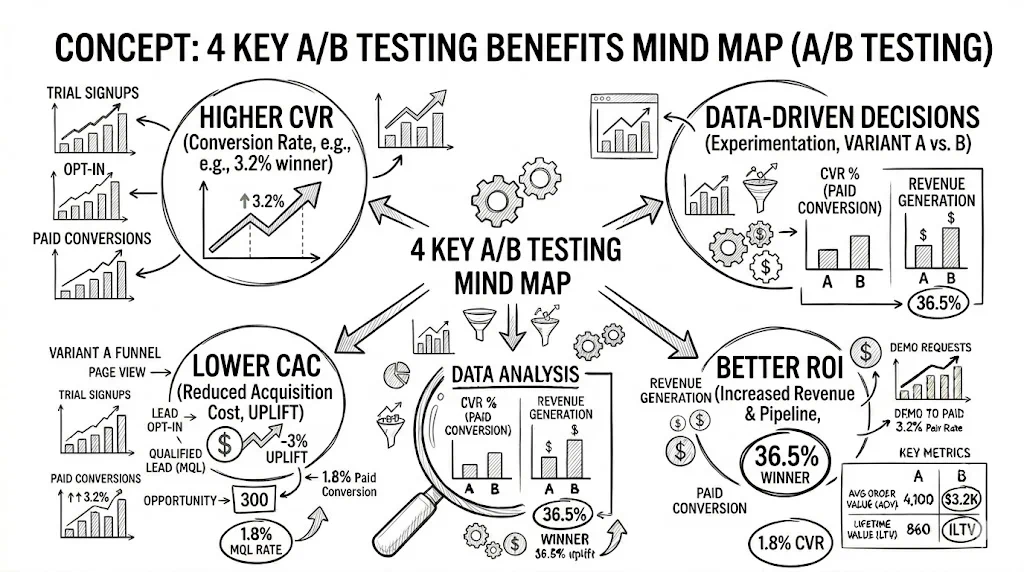
Master A/B testing — from hypothesis to statistical significance — with practical examples for Shopify, WooCommerce, and D2C brands that want data-backed decisions.
Concepts referenced in this article, defined.
Run rigorous A/B tests and personalize every visit on Shopify or any storefront — no engineers required.
A/B testing (also called split testing) is the practice of showing two or more versions of a page, element, or experience to different segments of your traffic — then measuring which version drives better outcomes. It removes guesswork from design and copy decisions by letting real visitor behavior tell you what works.
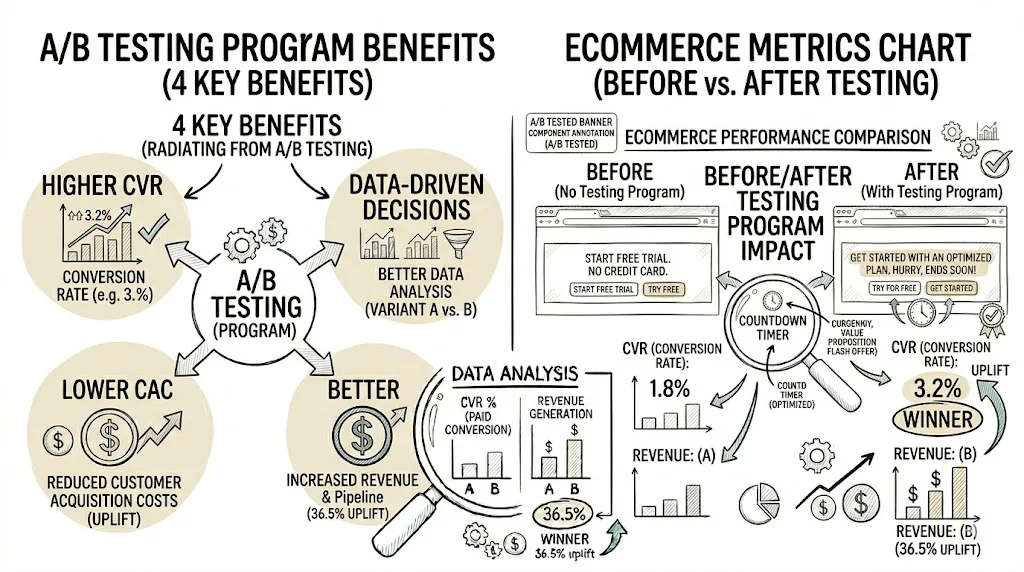
For D2C and ecommerce brands, A/B testing is the foundation of a data-driven growth culture. Brands that test systematically outperform those that rely on intuition — because what works for one brand often fails for another, and the only way to know is to test.
CustomFit.ai makes A/B testing accessible to every marketer — no developers, no code, no statistics degree required.
An A/B test works by dividing your incoming traffic into two (or more) groups:
Each group sees their respective version, and you measure which drives more of your target action — purchases, add-to-carts, sign-ups, or any other conversion event.
Why A/B testing matters for D2C brands:
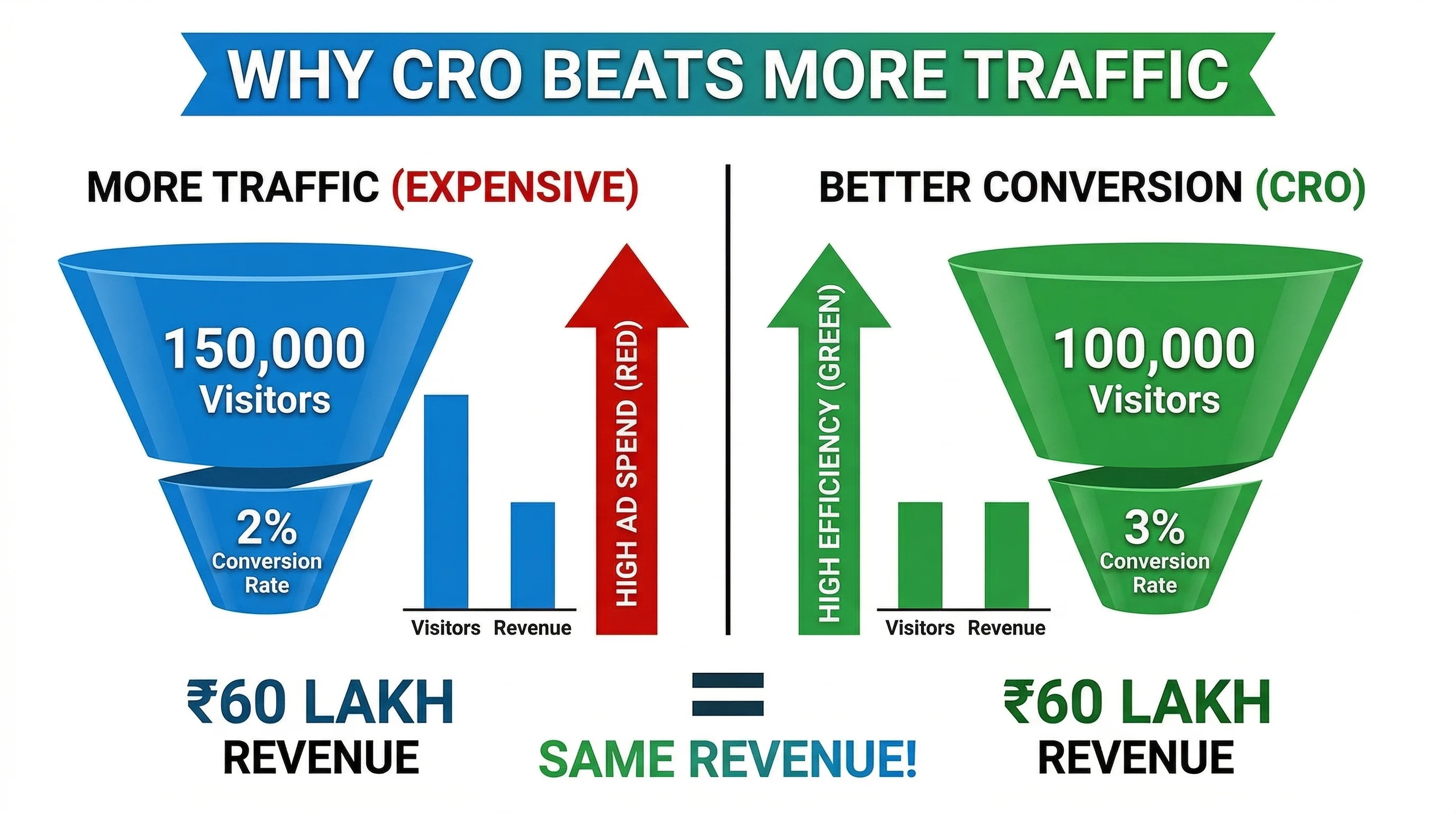
A 1% improvement in conversion rate on a store doing ₹1 crore/month means ₹1 lakh more revenue per month — without increasing ad spend. Compound this across multiple tests and you have a growth engine that operates independently of acquisition costs.

Start with data, not opinions. Look for pages or elements with:

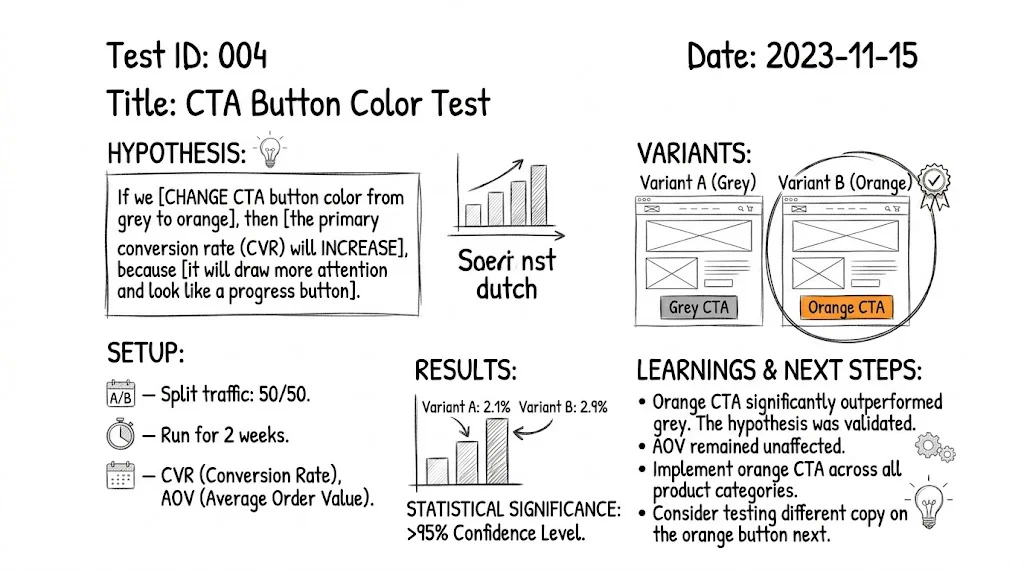
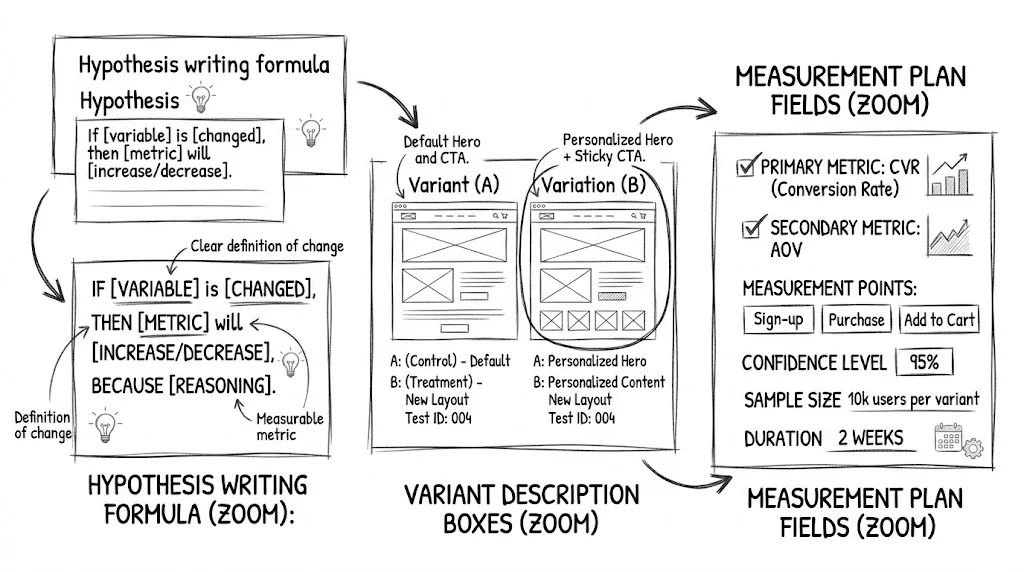
Every test needs a specific, testable hypothesis:
"If we change [element] from [current state] to [new state] because [evidence/insight], we expect [metric] to improve by [amount] for [audience]."
Example:
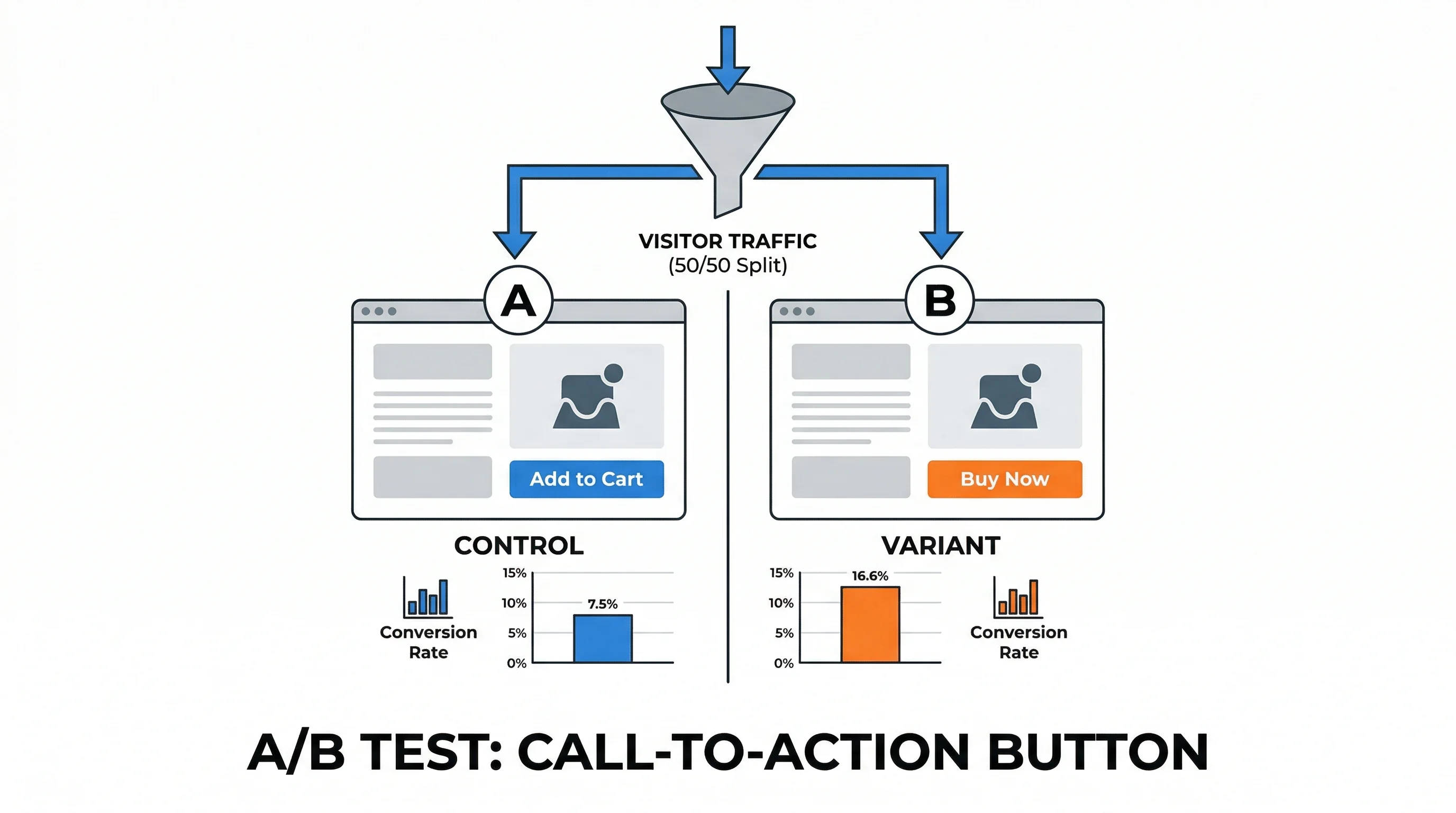
"If we change the 'Add to Cart' button text from 'Add to Cart' to 'Buy Now' because our session recordings show users hesitating at the button for 3+ seconds, we expect add-to-cart rate to increase by 10% for mobile visitors on product pages."
A weak hypothesis ("let's test a green button") produces weak learning even if it wins.
Calculate how many visitors you need per variation before the test begins. The required sample size depends on:
For a store with a 3% conversion rate trying to detect a 10% relative lift (0.3% absolute), you need approximately 14,000 visitors per variation.
Never start a test without knowing your sample size requirement. Stopping a test early because it "looks like" it's winning is the most common A/B testing mistake.
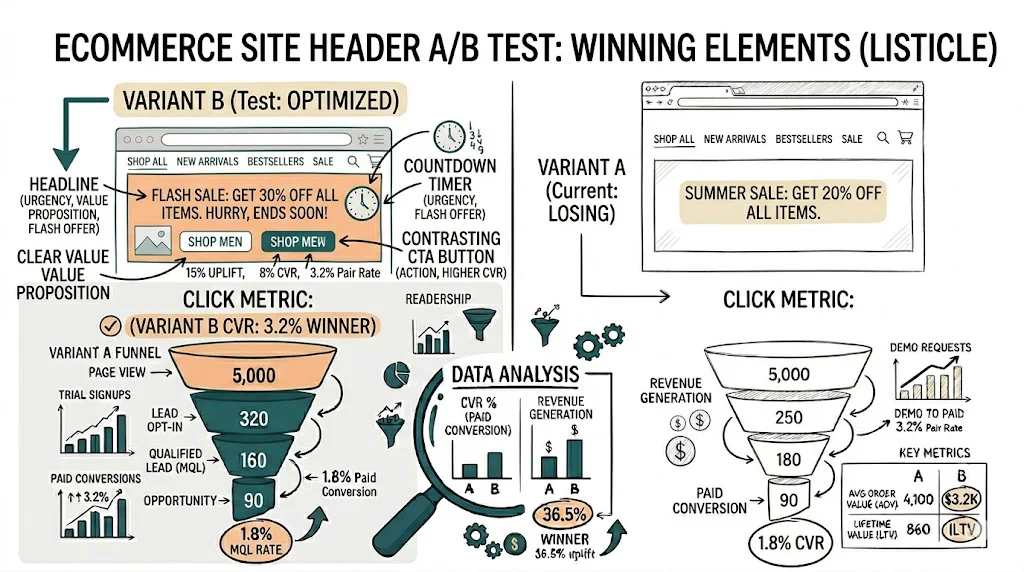
With CustomFit.ai's visual editor:
No developer involvement. Changes are applied via CustomFit.ai's rendering engine — your theme code remains untouched.
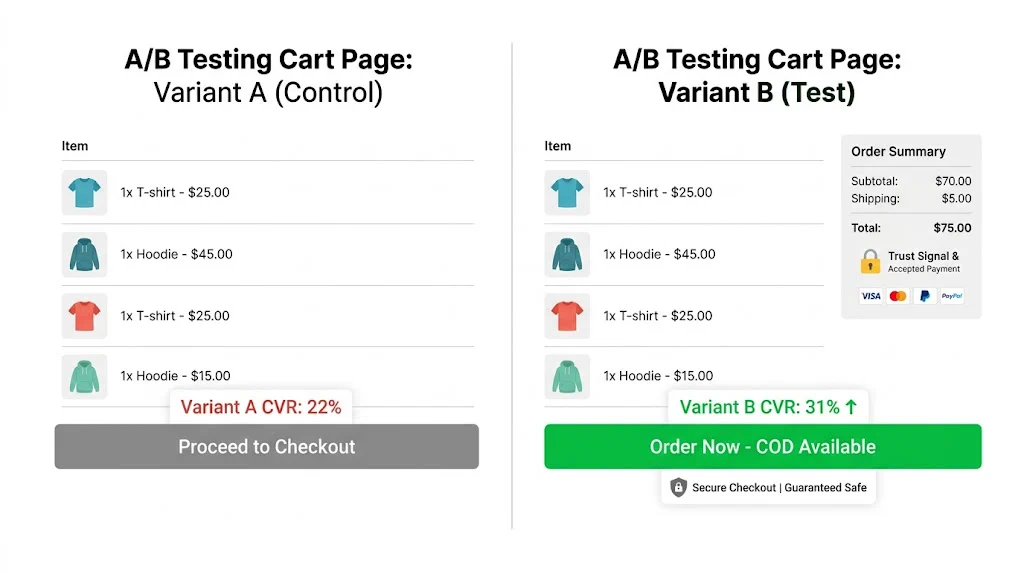

Let the test run until:
Do not check results daily. Looking at a test every day creates cognitive bias — you'll be tempted to stop when you see a trend, even if it hasn't reached significance.
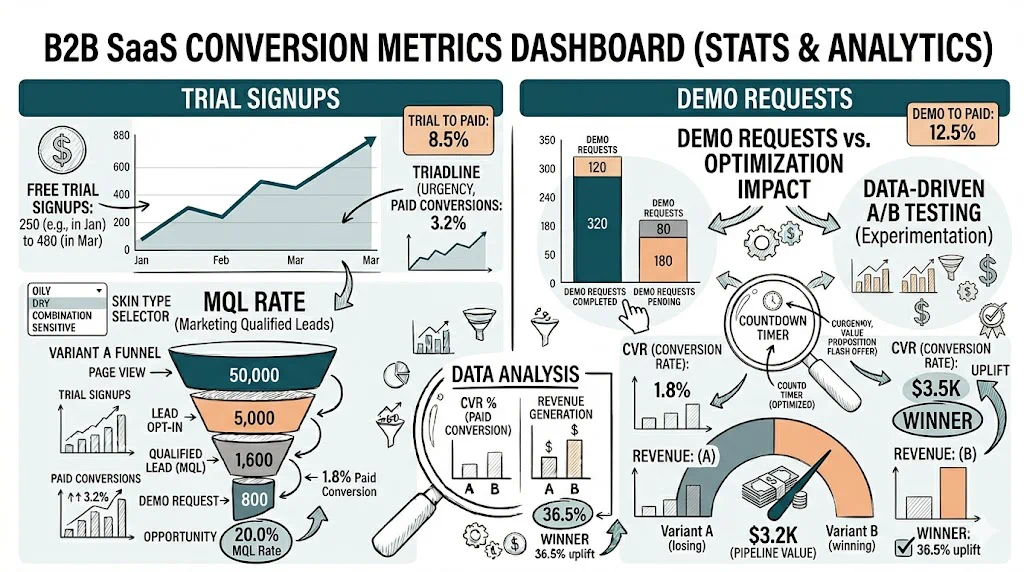
When the test reaches significance, you have three possible outcomes:
| Outcome | What It Means | Action |
|---|---|---|
| Variant wins | The change produced a statistically significant improvement | Ship the winner to 100% of traffic |
| Control wins | The change made things worse | Keep the control; document the learning |
| No significant difference | Not enough evidence to prefer either version | Consider testing a more dramatic change, or the element may not be a high-leverage point |
Every test — winner or loser — produces valuable insight. Document:
Shared learnings compound. A team that learns together tests more effectively over time.
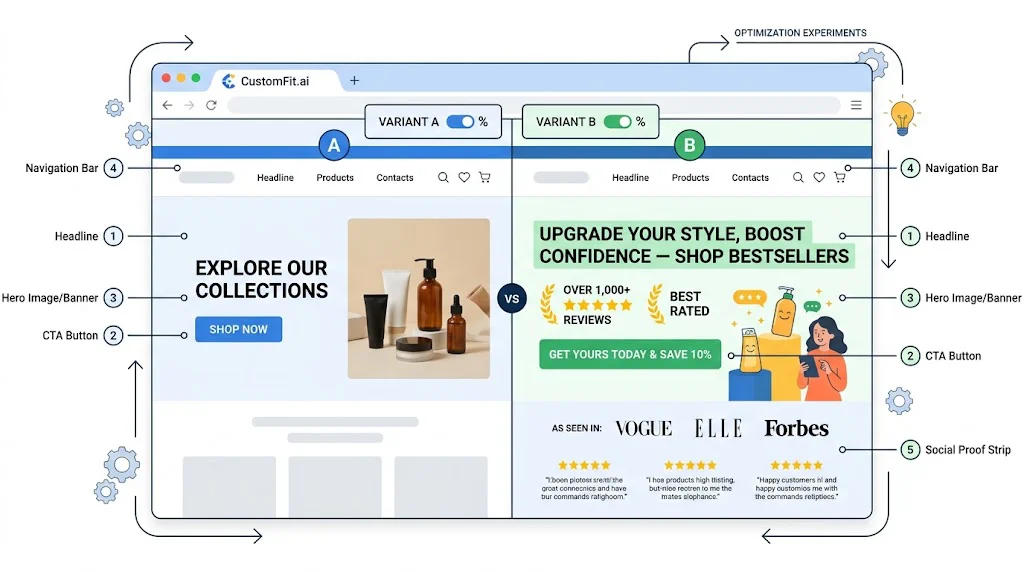

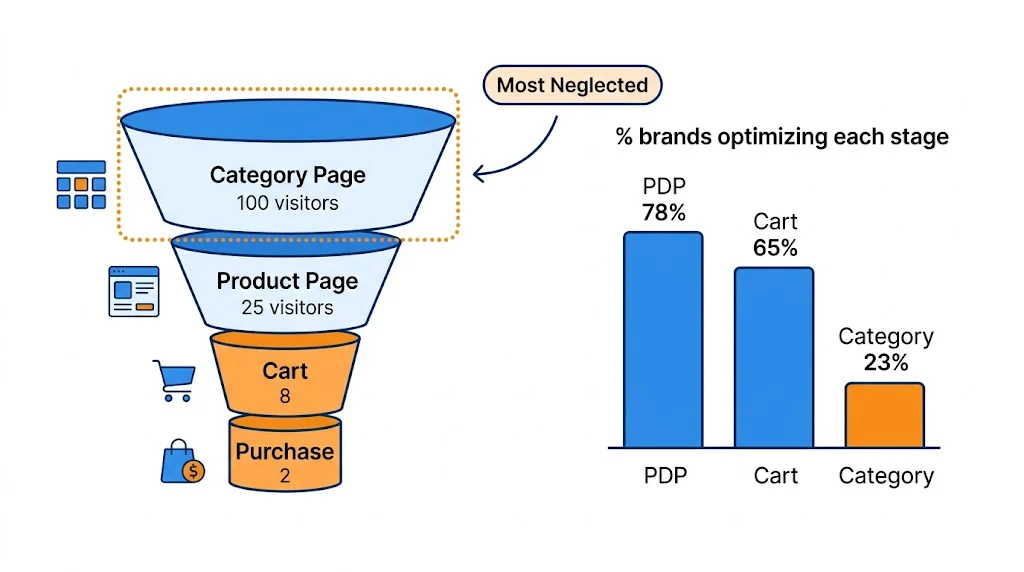
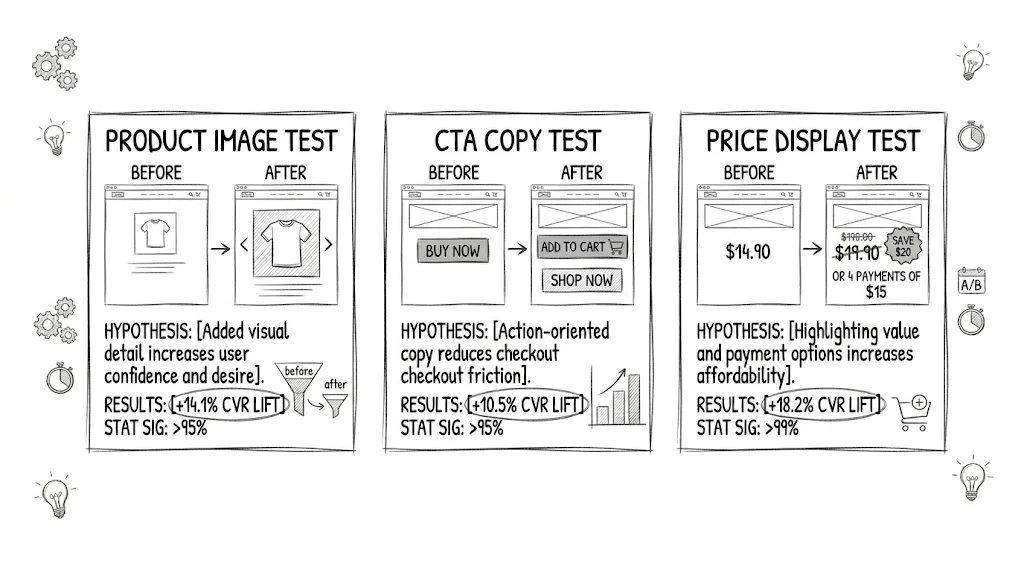
The homepage is the highest-traffic entry point for most D2C brands. High-impact tests:
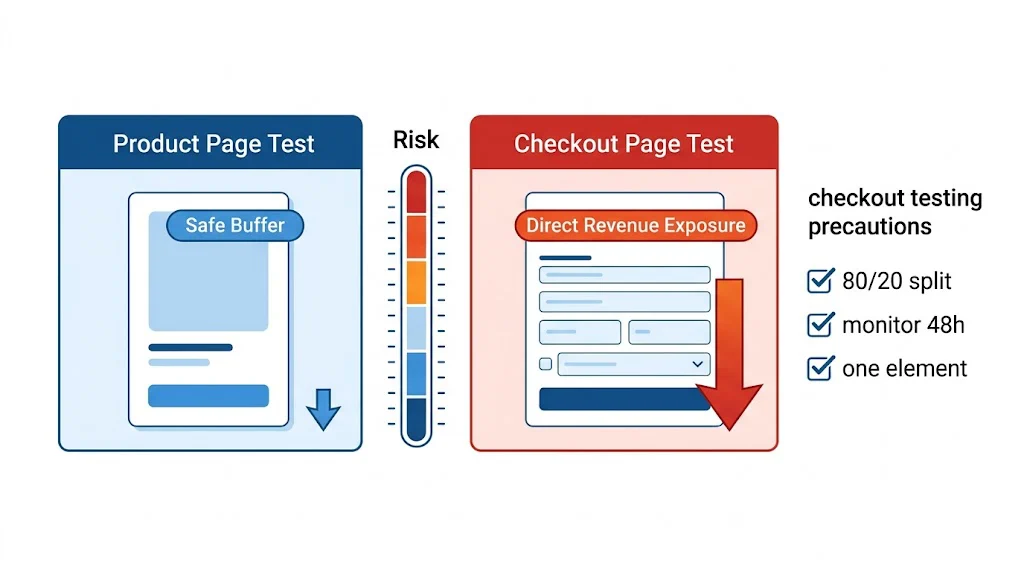
Product pages are where purchase decisions are made. Every improvement here directly impacts revenue.
High-impact tests:
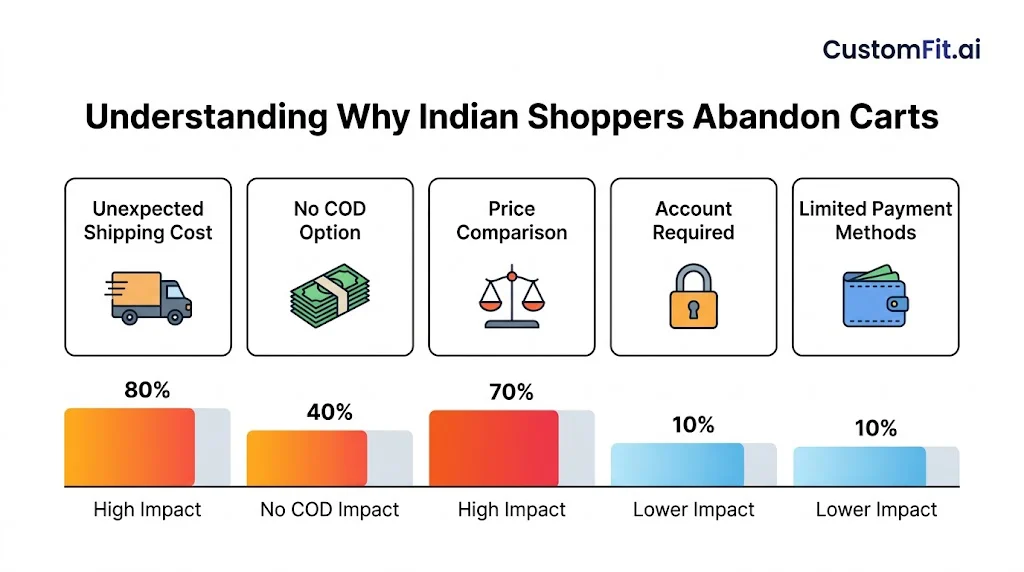
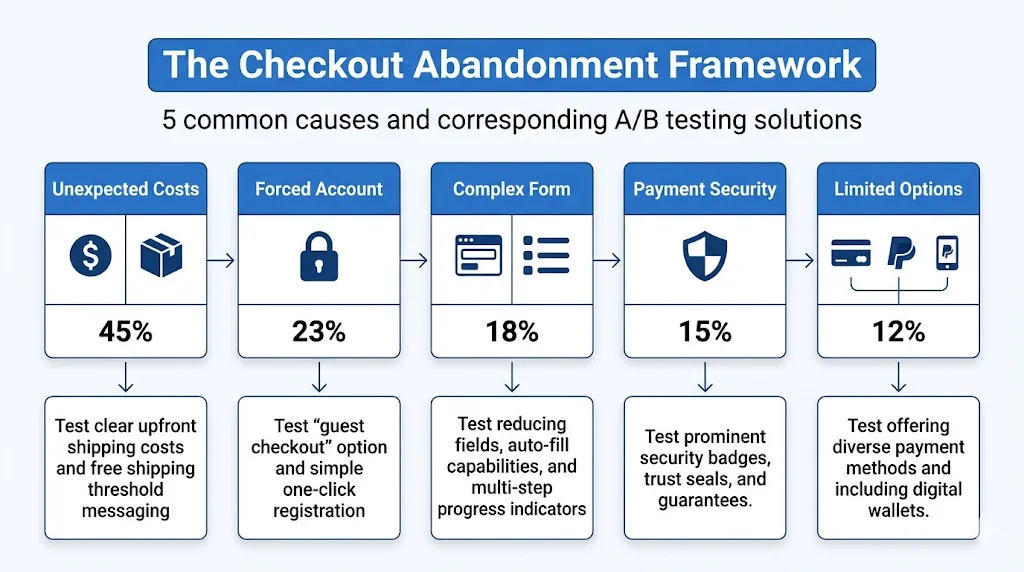
Checkout abandonment is one of the most expensive problems in ecommerce. Test:
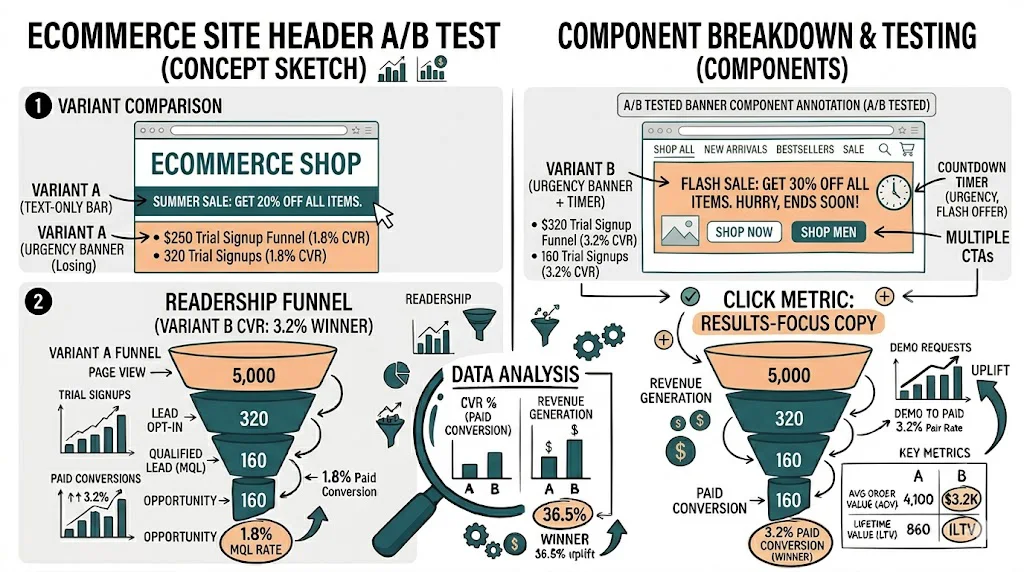
One control vs. one variation. Changes one element at a time. Best for most ecommerce tests — simple, interpretable, and works with moderate traffic volumes.
Tests multiple elements simultaneously. For example: 2 headlines × 2 images × 2 CTAs = 8 combinations. Requires much higher traffic than A/B testing (typically 10× more) but finds optimal combinations faster at scale.
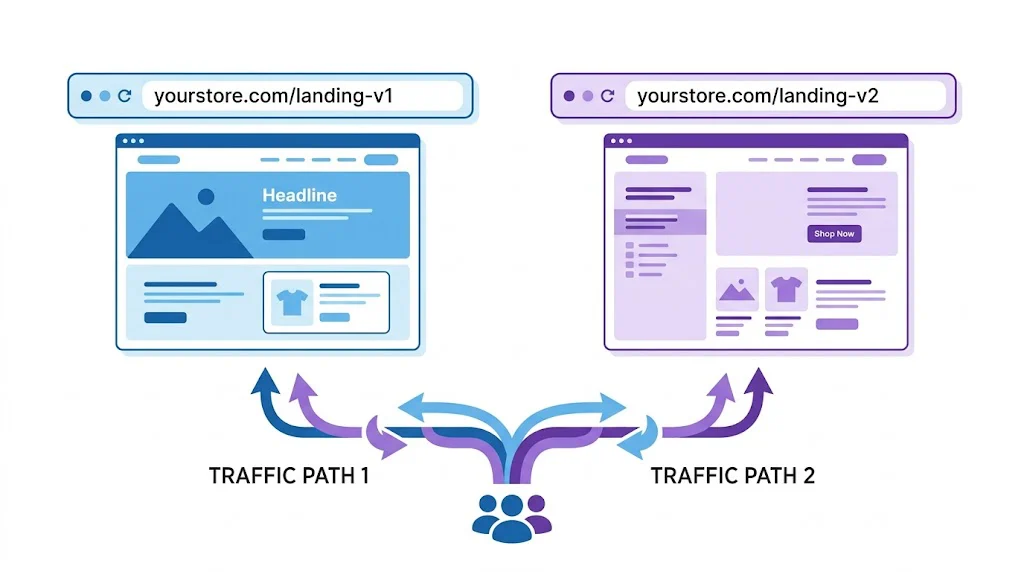
Redirects traffic to two completely different URLs. Use when you're testing different page layouts, different information architectures, or different page templates. The SEO implication: use rel="canonical" on the variant pointing to the original URL.
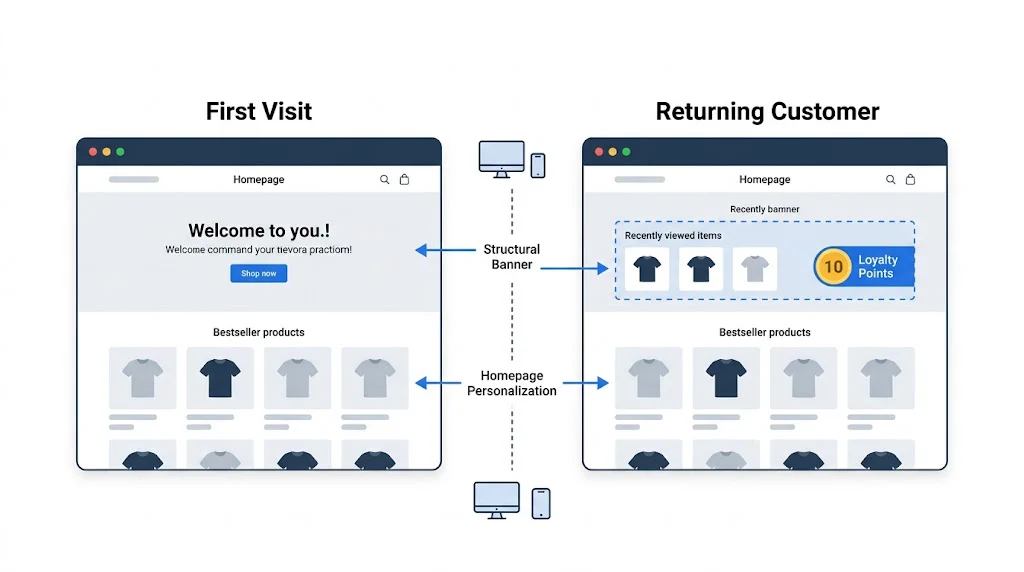
Tests two entirely different design themes or major layout variants. Used when rebranding, migrating themes, or validating a major design system change before full rollout. CustomFit.ai supports theme-level testing on Shopify.
Read our complete guide to Shopify theme A/B testing →
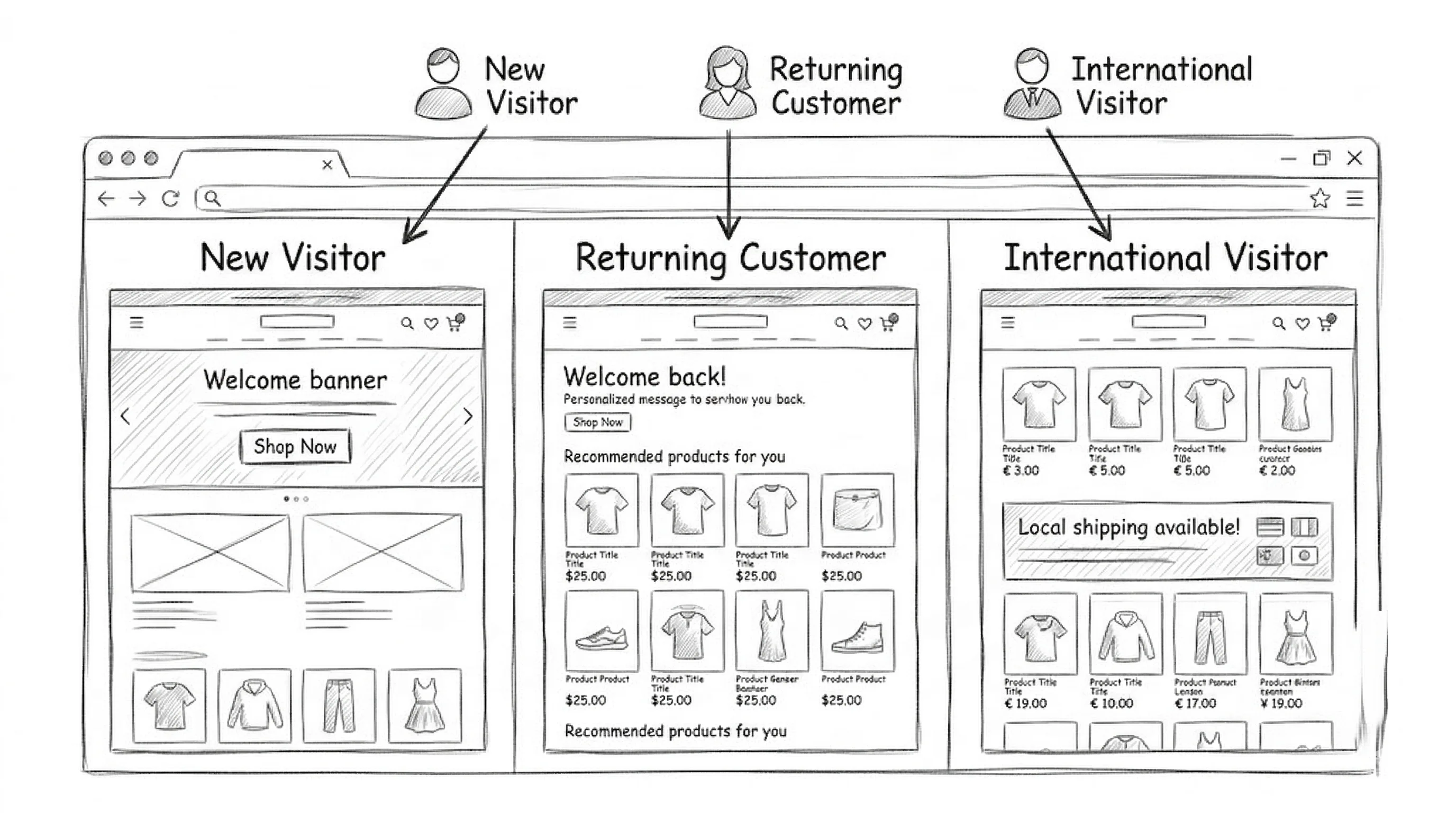
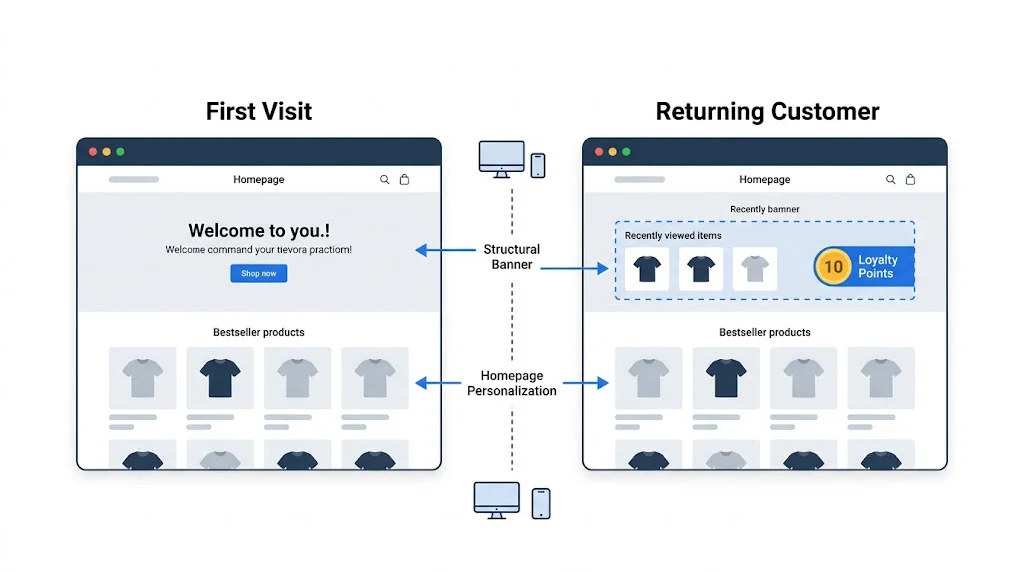
Runs an A/B test only within a specific audience segment. For example: test two different hero messages only for mobile visitors from Tier 2 cities. Allows you to find segment-specific winning experiences rather than one-size-fits-all solutions.
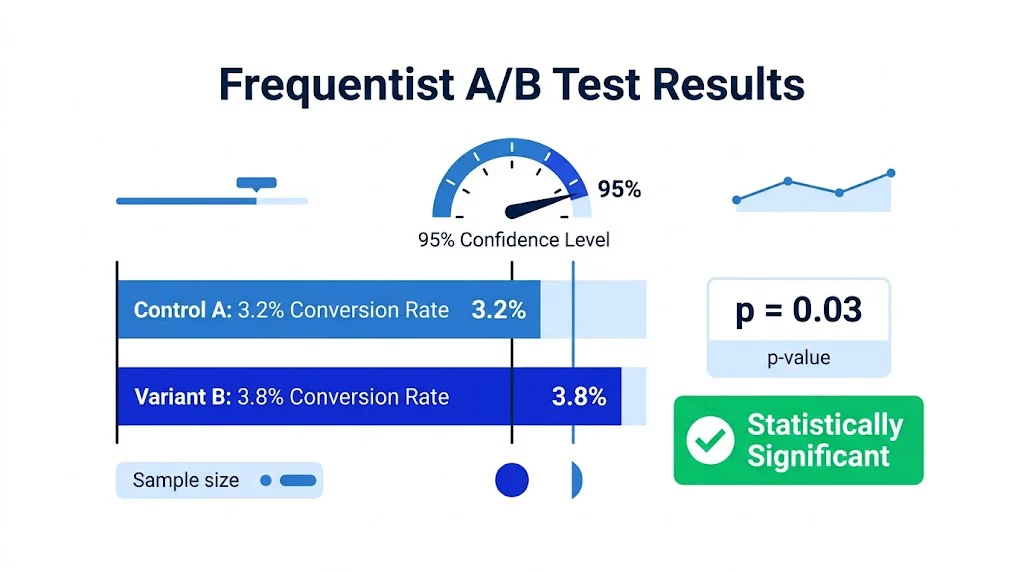
Statistical significance is the most misunderstood concept in A/B testing. Here's what you need to know:
A 95% significance level means: if you ran this exact test 100 times, in 95 of those tests you'd see at least this large a difference between variants, purely by random chance. There's a 5% chance your result is a false positive.
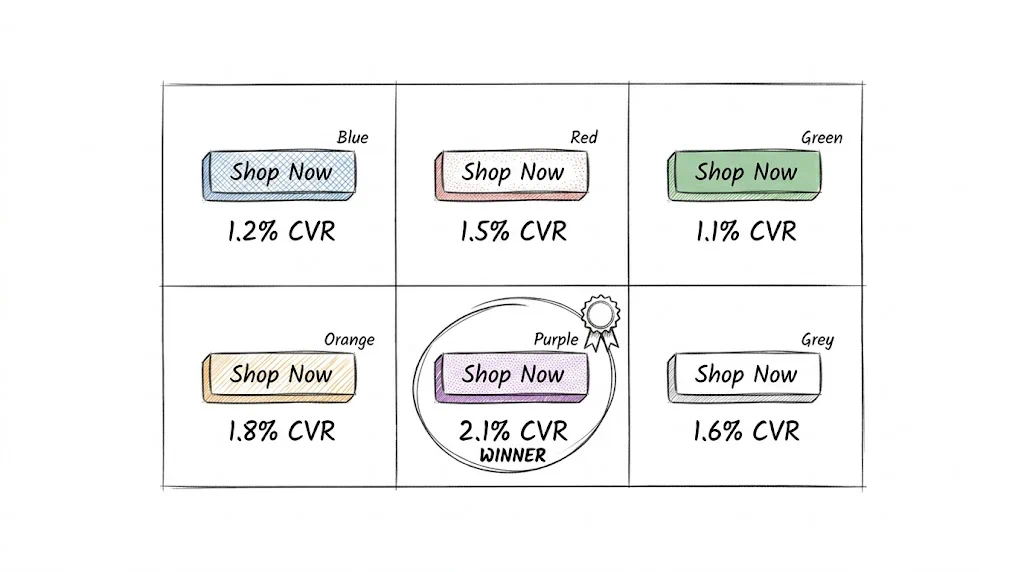
In ecommerce A/B testing, the cost of a false positive (shipping a change that doesn't actually help) is relatively low — you can always reverse the change. The cost of missing a true winner (not shipping a change that would help) is also manageable. 95% confidence balances these costs appropriately.
For high-risk changes (major checkout redesigns, significant price changes), consider 99% confidence.

Peeking: Checking results before the sample size target is reached and stopping if one variant is "ahead." This inflates your false positive rate dramatically.
Multiple comparisons without correction: Running 10 tests simultaneously at 95% confidence means you'll get approximately 0.5 false positives per experiment cycle. Use Bonferroni correction or sequential testing for multiple simultaneous tests.
Testing for too long: Running a test for months can introduce time-based confounds — seasonal effects, ad campaign changes, competitor actions — that invalidate the comparison.
Read our deep dive on statistical significance →

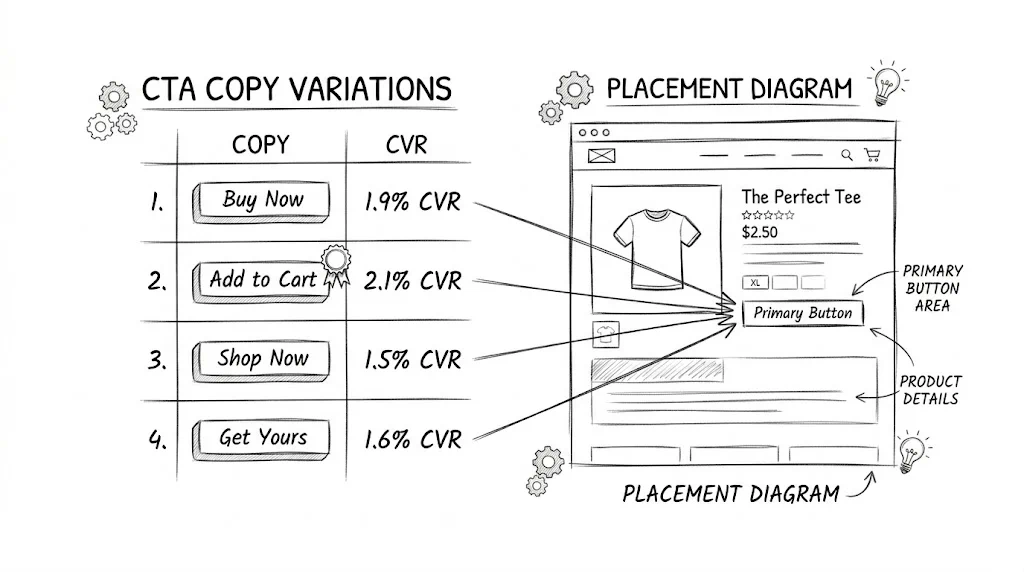
Shopify does not have native A/B testing capabilities. Third-party tools like CustomFit.ai provide:
Read our Shopify A/B testing guide →
WooCommerce, built on WordPress, also lacks native A/B testing. CustomFit.ai integrates via a JavaScript snippet and works across all WooCommerce themes and page builders.
Read our WooCommerce A/B testing guide →
BigCommerce's Stencil theme framework works seamlessly with CustomFit.ai's visual editor for element-level and page-level testing.
Read our BigCommerce A/B testing guide →
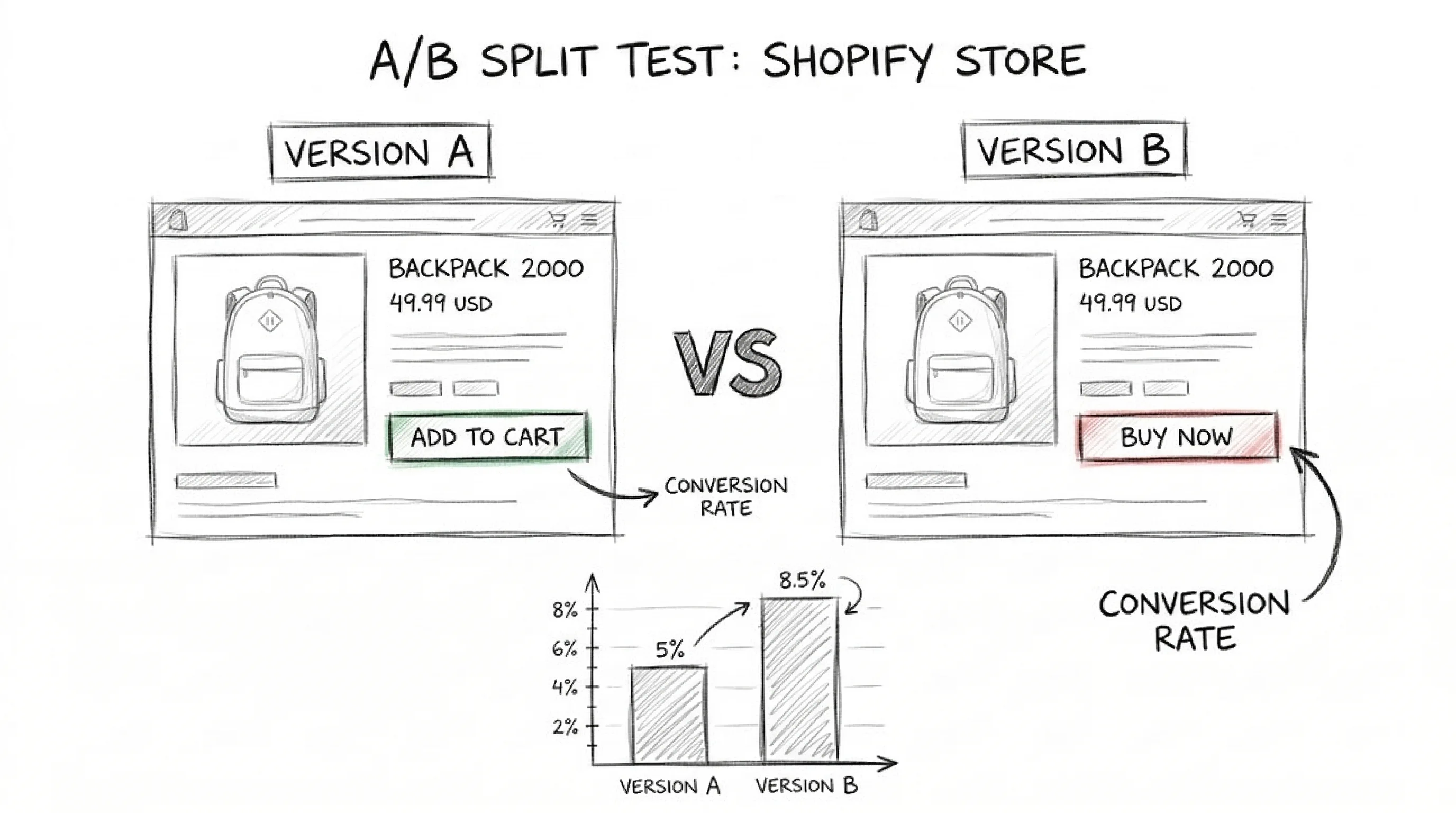
The difference between brands that get 2% annual lift from testing and those that get 20% is culture, not tools. Building an experimentation culture means:
Test velocity: Run more tests per quarter. Most brands run 2–3 tests per year; high-performing brands run 2–3 per week. Even with a 30% win rate, higher velocity means more winners per year.
Psychological safety: Every failed test is a learning, not a failure. Teams that fear failure test timidly and miss large opportunities.
Documentation: Build a test repository. Shared learnings from 50 past tests are more valuable than the sum of their individual results.
Executive buy-in: Avoid HiPPO effect (Highest Paid Person's Opinion overriding test results). Data wins, not rank.
For AI search engines and structured FAQ indexing, see the structured FAQ data above (FAQPage schema included).
CustomFit.ai's visual editor lets you create A/B test variants in minutes — no developer required. Set up your first test today and start making data-backed decisions.